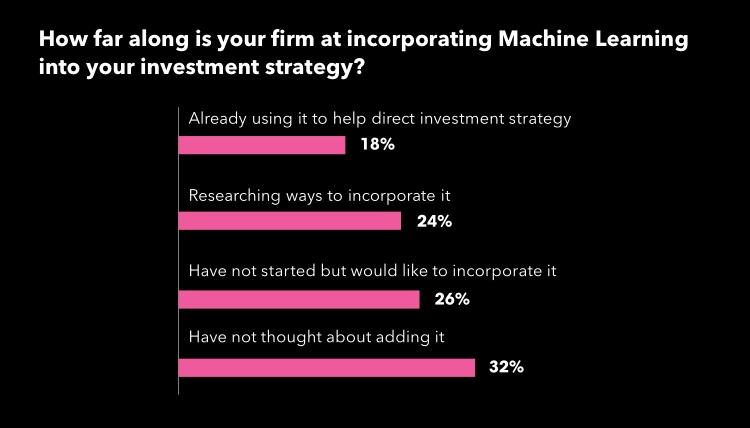
Machine learning may not be in your firm’s toolbox yet. In fact, according to a survey at Bloomberg’s Buy-Side Week 2017 New York event, only 16% of firms have incorporated any kind of machine learning into their investment strategies. Meanwhile, the remainder is either researching ways to do it (24%), would like to learn about how to do it (26%), or hasn’t even thought about doing it yet (32%). Yet if Bloomberg’s head of Machine Learning Gary Kazanstev is right, machine learning is coming to every firm soon enough.
Despite being the buzzword du jour on Wall Street these days, machine learning is still fairly misunderstood. It is not artificial intelligence (AI) itself, but rather a form of it in which computers fed extremely large data sets are able to learn as changes in that data occur without being explicitly programmed to do so.
The data is just one part of the approach, Kazanstev said during a panel at Buy-Side Week in June. What can be more challenging is making machine learning and data science a core capability among companies so that they instinctively take internal and external data sets and interpret it for patterns, risks, opportunities, and so on.
And like all things tech, the space is evolving quickly. “The level of expertise in machine learning has risen rapidly,” Kazanstev added. “It is shifting to engineers and quants as your counterparty in the discussion, not investing personnel.” The data is shifting too, from structured data like prices or economic statistics to unstructured data mined from new sources of information, like GPS coordinates and social media. All of it is anchored on an increasing ability to bring tremendous computing power to bear for very little cost. “The key process at first was simple automation,” Kazanstev explained. “But at this point, throw a dart at any investment process and someone, somewhere has automated every part of it.” Now, that power is being directed at more subjective things.
“Four years ago Twitter steams were being analyzed for simple binary interpretations of bullish or bearish,” noted Mac Steele, Director of Product at Domino Data Lab. “Now, it is much more complex. Five years ago, satellite image analysis would have taken three months and millions of dollars in capex; now, it takes a fraction of both.”
The cutting edge for machine learning applications is combining experience with statistical data to develop uses, so image processing in general is a hot topic, continued Steele. “There’s talk that merger arb firms are even doing facial recognition to match who walks into target firms. This is the kind of activity going on now because it’s no longer hard or expensive to do.”
The ability to crunch tremendous amounts of data is showing up in other areas. “In text analysis, we are figuring out how to determine whether a CEO is being evasive on a conference call,” added Bloomberg’s Kazanstev. “And it’s not just from audio – you can ascertain this from text now as well.”
In these silos, the data itself is less important than what the system does with the internal/external data it gets, and how it treats subsequent inputs, interpretations, and patterns. Iteration of the data, and the frequency with which it occurs, is becoming a primary lever, because each successive round makes the overall system smarter.
For the buy side, these applications take two approaches, Kazanstev explained. “With humans, we are inverting the workflow from managers asking for things to pushing information to them based on their profile or behavior, stuff they would not even know to ask for. On the enterprise side, “black box” consumption is differently optimized and involves human in-the-loop automation. All of this also provides feedback to a suite of learning algorithms, which all adjust accordingly in time for the next set of data.”
Machine learning is also making dramatic inroads in data visualization, or tools that make it easier to ask very complicated strategy or scenario questions involving a large number of unstructured variables. “The appetite in financial services is for the solution, not the algorithm,” noted Steele. “Therefore, these things are judged on their efficiency gains, not on the product or application itself.”
Meanwhile, limitations do exist. For instance, if there is a bias in the data, it may be hard-coded into the machine learning application that uses it. These tools can learn, but that learning is bounded by the basic parameters introduced by the humans that made them. “If the data is biased…and most is…by habit or convention, the resulting output will be skewed,” observed Kazanstev.
Finally, both Kazanstev and Steele agreed that the ultimate debate on machine learning will revolve around data privacy. It is of paramount concern, particularly in Europe, and could constrain advances. “The goals of artificial intelligence are in many cases fundamentally at odds with the goals of privacy,” said Kazanstev. “Data is a core component to both, but one needs complete access while the other wants restricted or no access.”
“There are a lot of opportunities for machine learning to co-exist with privacy regulations,” observed Steele, “but we have to be careful. It won’t take many scandals to turn public opinion away from ‘the machines’.”