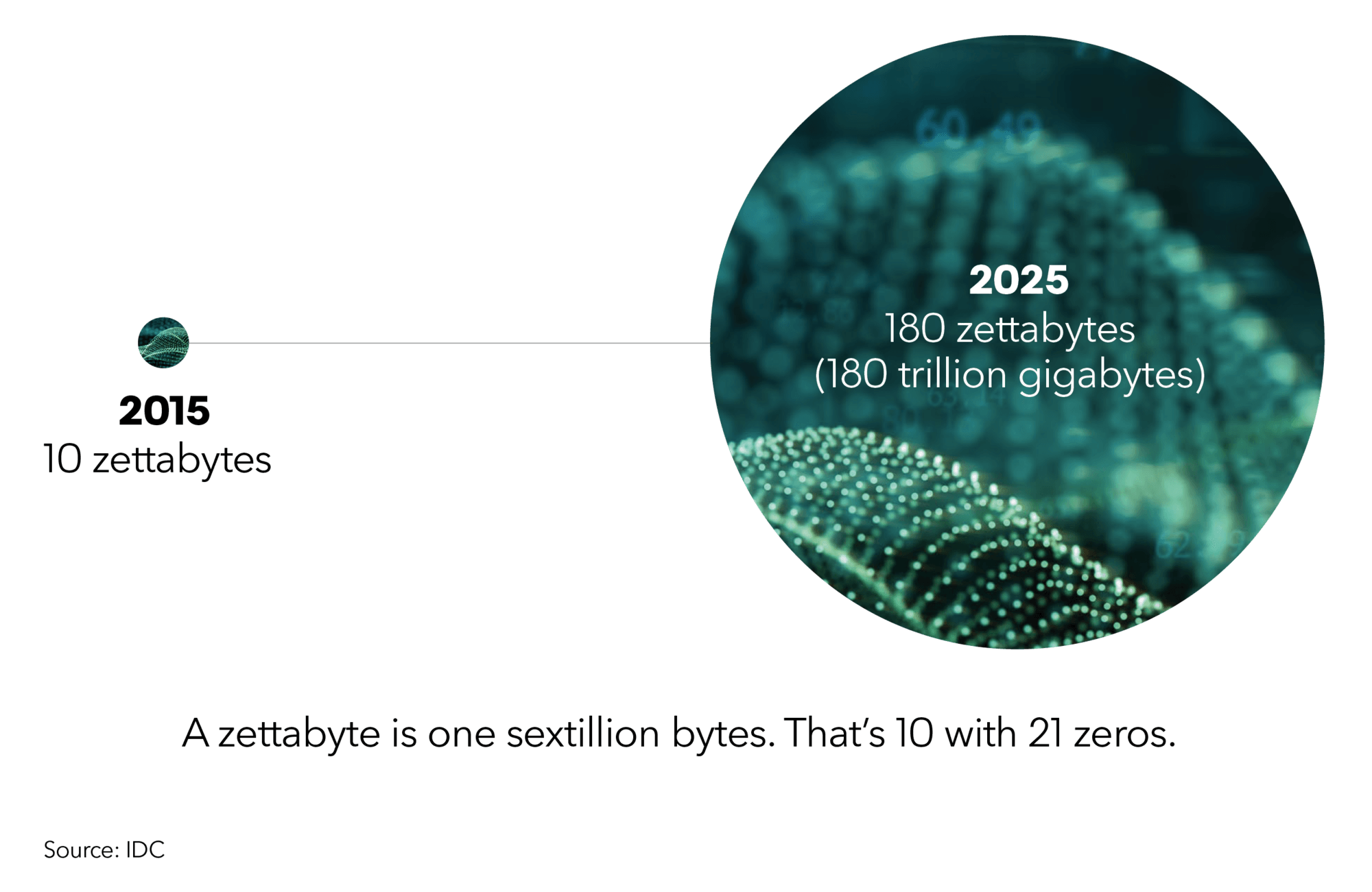As the world of data grows at an almost incomprehensible rate, companies are sitting on enormous data reserves that, as yet, remain untapped.
The world of data is growing at an almost incomprehensible rate: the size of the digital universe will double every two years at least.
As a result of data proliferation, many companies are sitting on enormous untapped data reserves, but they are often scattered and in incompatible data formats.
Companies with a data capitalization strategy are investing to insure they can extract as much value from their data as possible. A key component of any sound data strategy includes a robust data quality process.
It is tempting for companies to consider short-term solutions and manual processes for data scrubbing, but for any long-term and repeatable data-related strategy, an algorithmic approach is appropriate.
Both a challenge and an opportunity
For financial services firms in particular, big data presents both a challenge and an opportunity. Currently, businesses have more data at their fingertips than ever before, but understanding and effectively using this data can still be difficult.
According to Matthew Rawlings, Head of Data License at Bloomberg, problems arise from the fact that “it takes a lot of manual effort to clean and run that data and add some business intelligence on top of it.”
Many firms have faced a time lag in making data-driven decisions — by the time the data is located, tidied, sorted and applied, it is virtually out of date and no longer relevant. Firms can run into significant issues — both regulatory and business-related — if their data quality is not up to scratch.
Indeed, in a pre-conference survey of delegates heading to the 2017 North American Financial Information Summit, just over half (51%) cited data quality as their biggest immediate hurdle.
A year-long process — in a day
Perhaps due to some of these drivers, a growing number of early adopters are turning to machine learning, a process that utilizes sophisticated artificial intelligence to effect something of a technological revolution in the data-quality world. AI’s capabilities are at the tipping point of exponential adoption and impact.
To illustrate this, imagine a large bank that regularly deals with NatWest (National Westminster Bank). Across different business units, databases and spreadsheets, there can be many variations on the same client name — perhaps simply appearing as County NatWest, Nat West or National Westminster and so on. Reconciling all of these entries would take significant manual work.
But a computer program can theoretically scan and process data from across the bank and deliver all of the matches in a matter of hours. “Suddenly the bank can see instantly, at a corporate level, its entire exposure to NatWest,” explains Rawlings. “This enables faster, better decision-making,” he added.
This process, or name-identity recognition, is just one of the areas where machine learning is capable of making a radical difference. And the process improves over time.
In the NatWest example, the original scan may flag say 10% or 15% false positive matches on its first attempt. Through continuous feedback, it is then capable of learning from the false positives and applying the adjusted rules to the next set of data. This constant evolution is what makes machine-learning technology so effective at scrubbing and verifying data at speeds previously thought impossible.
Ensuring data quality with machine learning
Using technology of this kind can ensure data quality across the enterprise. During a webinar, John Randles, Chief Executive Officer at Bloomberg PolarLake, recalled the story of a large global asset manager.
“We discovered millions of mismatches between the metadata which was describing that data and the actual source data itself and over a 15-month period eliminated these issues,” crunching the number of problems with the dataset down from the millions into the thousands.
Using the right technology can provide a firm with one of its core needs — data in context. Context is the most important aspect of getting staff to appreciate data quality, according to Sanjay Saxena, Head of Enterprise Data Governance at Northern Trust Corporation. “When you can explain it in terms of their day-to-day job, you see the light bulb come on,” he said during the webinar.
Data management best practices have been significantly improved by a combination of the plummeting cost of computer processing power, increasing availability of data, and the democratization of open-source machine-learning tools, which allow any company to become AI-enabled.
The new data science methods and best practices allow for the distillation of billions of data cells and rows into meaningful insights. Data quality will continue to be a differentiator for any institution’s data insights.
Ultimately, humans cannot scale at the rate needed to interpret data in zettabytes, which is why a foundation of machine learning is so important.